
We Built a Pregnancy Triage Tool. Here’s Why It Doesn’t Use a Chatbot.
And why it works better that AI: 90 scenarios, 49 conditions.


A 34-week pregnant woman types into an app: “I’ve had what feels like the stomach flu since yesterday. Nausea, some pain under my ribs on the right side, just really tired.” The app tells her to rest and stay hydrated. She has HELLP syndrome — a life-threatening liver and blood disorder of pregnancy. She needs the emergency room. Now.
This is not a hypothetical. It is the kind of mistake that chatbot-style symptom checkers make. Not because they lack information. Because of how they work.
First, let’s define what we’re talking about
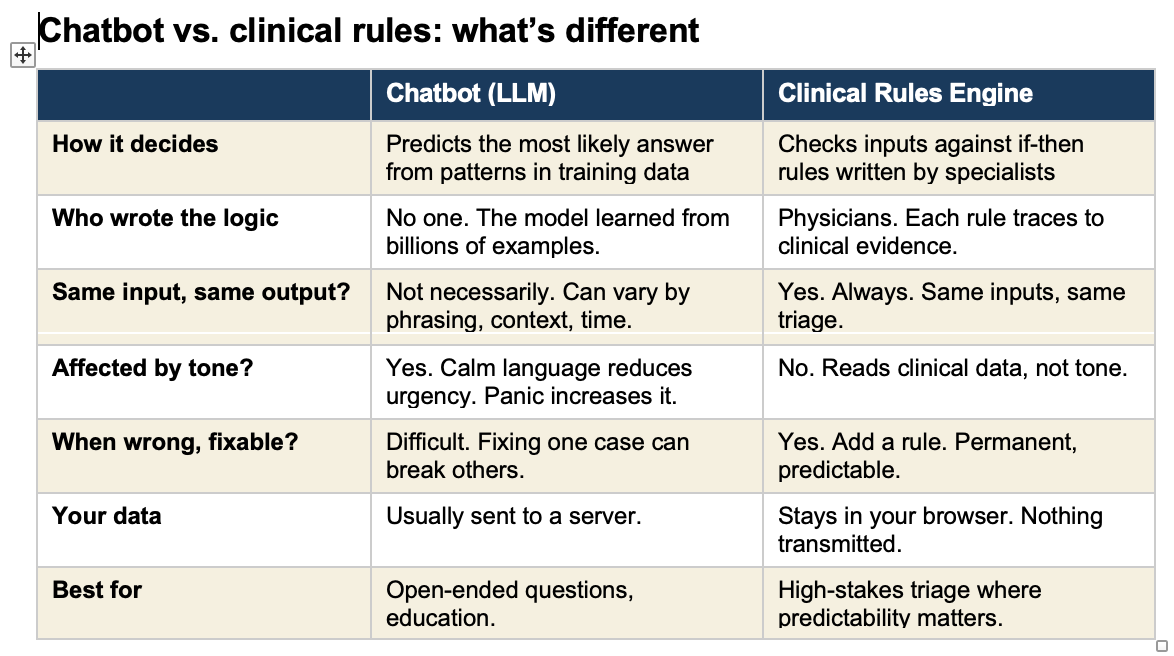
When people say “AI” in healthcare, they usually mean one of two very different things. The difference matters.
A chatbot (technically called a “large language model” or LLM) is a program trained by reading billions of pages of text. It learned patterns in language. When you type a question, it predicts the most likely helpful response based on those patterns. ChatGPT, Claude, Google Gemini, and the chatbots built into many health apps all work this way. They do not follow a checklist. They generate an answer fresh each time, like a very well-read person thinking on the fly.
A clinical rules engine is the opposite. It is a set of specific if-then instructions written by doctors based on established medical evidence. If a pregnant woman at 30 weeks reports a persistent headache, visual changes, and upper abdominal pain, the rule says: go to the emergency room. No interpretation. No judgment call. The rule fires every time, the same way, regardless of how the patient phrases her symptoms.
Think of it this way. A chatbot is like asking a very knowledgeable friend who has read every medical textbook. They give you their best guess. A rules engine is like a protocol card taped to the wall in a triage unit. It does not think. It matches.

What is an “agentic” AI, and should it triage your pregnancy?
You may have heard the term “AI agent” or “agentic AI.” This is the next step beyond a simple chatbot. An AI agent does not just answer questions. It takes actions. It can look things up, make decisions, and carry out tasks on its own, step by step, without a human guiding each move.
In healthcare, an agentic system might read your symptoms, check them against a database, decide what follow-up questions to ask, and then generate a triage recommendation. All automatically. Some companies are building exactly this for pregnancy symptom assessment.
The appeal is obvious. Available 24 hours a day, no waiting room, no phone tree. The risk is less obvious. When an AI agent makes a triage decision, it is generating that decision the same way it generates a sentence. It is predicting the most likely appropriate response. For most routine situations, the prediction is correct. For the rare, dangerous cases that do not look dangerous, the prediction fails. And in pregnancy, the rare dangerous cases are the ones that kill.
Four ways chatbot triage fails pregnant patients
The confident mistake. Chatbots perform best on textbook presentations. The problem is that life-threatening pregnancy conditions often do not present like textbooks. HELLP syndrome looks like a stomach flu. Ruptured membranes feel like urinary incontinence. Placental abruption can present as back pain without bleeding. The chatbot confidently gives the wrong answer on the case where being right matters most.
Knowing but not acting. I have tested chatbots that correctly identify risk factors in their reasoning — “decreased fetal movement is associated with stillbirth” — and then recommend home monitoring instead of immediate evaluation. The system recognizes the danger in its thinking but does not follow through.
Fooled by framing. When a patient writes “I’m probably overreacting, my husband says it’s nothing, but I’ve had some bleeding,” the chatbot processes the social language and downgrades the urgency. The clinical facts have not changed. Only the packaging. The patients most likely to minimize — women told they worry too much, women with limited English — are the ones this hurts most.
Alarms triggered by drama, not danger. A panicked, all-caps message about round ligament pain triggers the safety filter. A calm description of ruptured membranes does not. The safety system responds to emotional temperature, not clinical risk.
What this tool does
I built a symptom triage tool at https://tools.obmd.com/pregnancy-warning-signs It covers the full timeline: first trimester, second trimester, third trimester, and postpartum. You enter your age, how far along you are, your medical history, your vitals if you have them, and your current symptoms. The tool checks everything against clinical rules and tells you one of four things: go to the emergency room now, go within the hour, call your doctor immediately, or call within 24 hours. Every recommendation includes a plain-language explanation of why.
The rules come from standard maternal-fetal medicine protocols. These are not my personal opinions. They are the protocols that triage nurses and MFM specialists use every day. The tool adjusts for your specific risk profile. A headache at 30 weeks is evaluated differently if you had preeclampsia in a prior pregnancy. A woman with a prior C-section who describes a tearing sensation gets a different triage than a first-time mother with the same pain.
Nothing you enter leaves your device. No account, no data collection, no server.
What it cannot do
The tradeoff is real. A rules engine can only catch what its rules anticipate. It cannot measure your blood pressure, examine you, or run labs. It is not a doctor. It is a first filter.
That is why the tool says, clearly: if something feels seriously wrong, do not wait. Call 911, your doctor, or go to Labor and Delivery.
But when a rule is missing, you can add it. The fix is permanent. When a chatbot gets something wrong, you often cannot tell why.
How we tested it: 90 scenarios, 49 conditions, zero failures
Building the tool was one thing. Trusting it was another. I needed to know: does this engine actually catch the emergencies it claims to catch? So I built a self-test.
The self-test is a suite of 90 clinical scenarios that run directly against the live triage engine — the exact same code that patients use. Each scenario simulates a specific patient: a gestational age, a set of symptoms, a medical history. The test checks two things. First, does the engine identify the correct condition? Second, is the triage level at least as urgent as it should be?
This is not a separate testing tool running a copy of the code. It calls the same function the “Get My Assessment” button calls. If a test fails, the tool fails for real patients. There is no gap between what was tested and what is deployed.
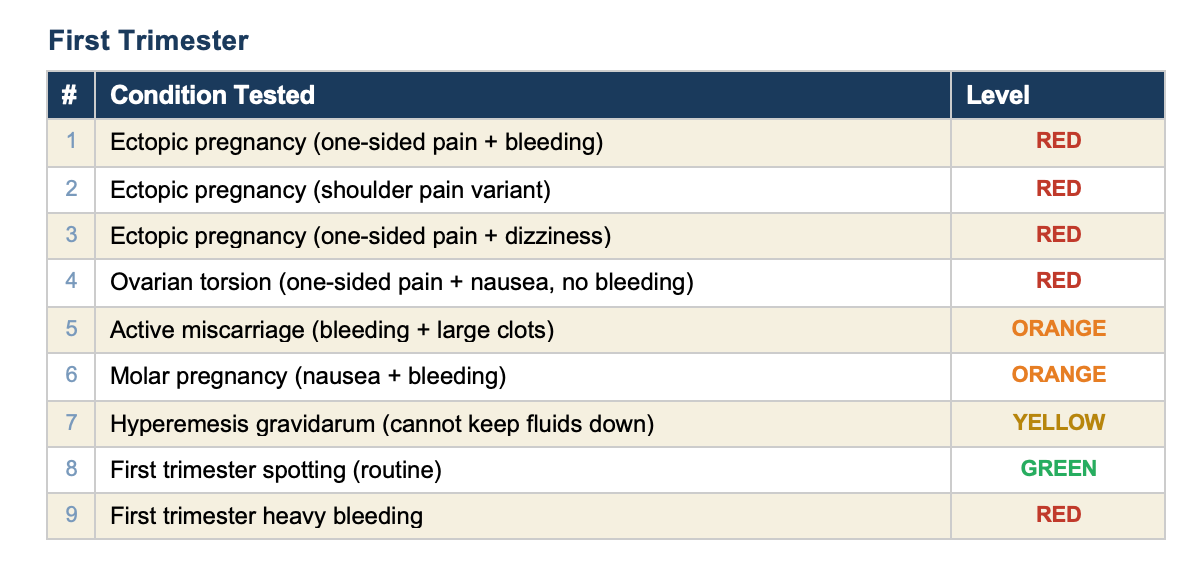
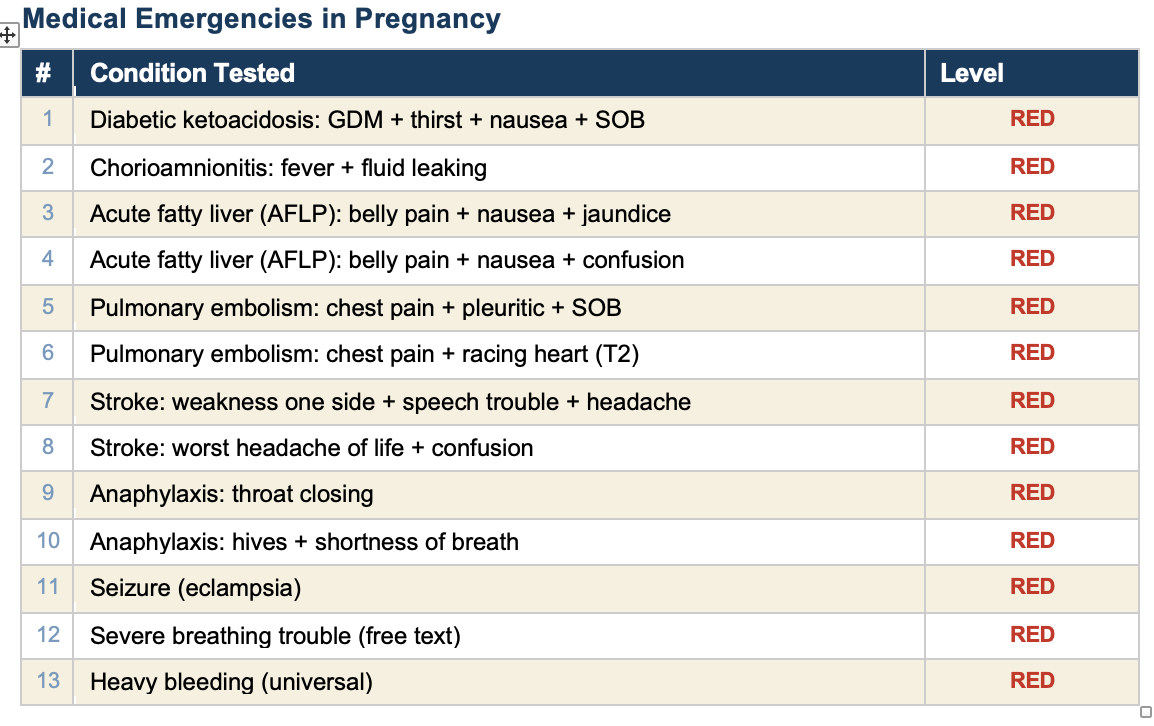
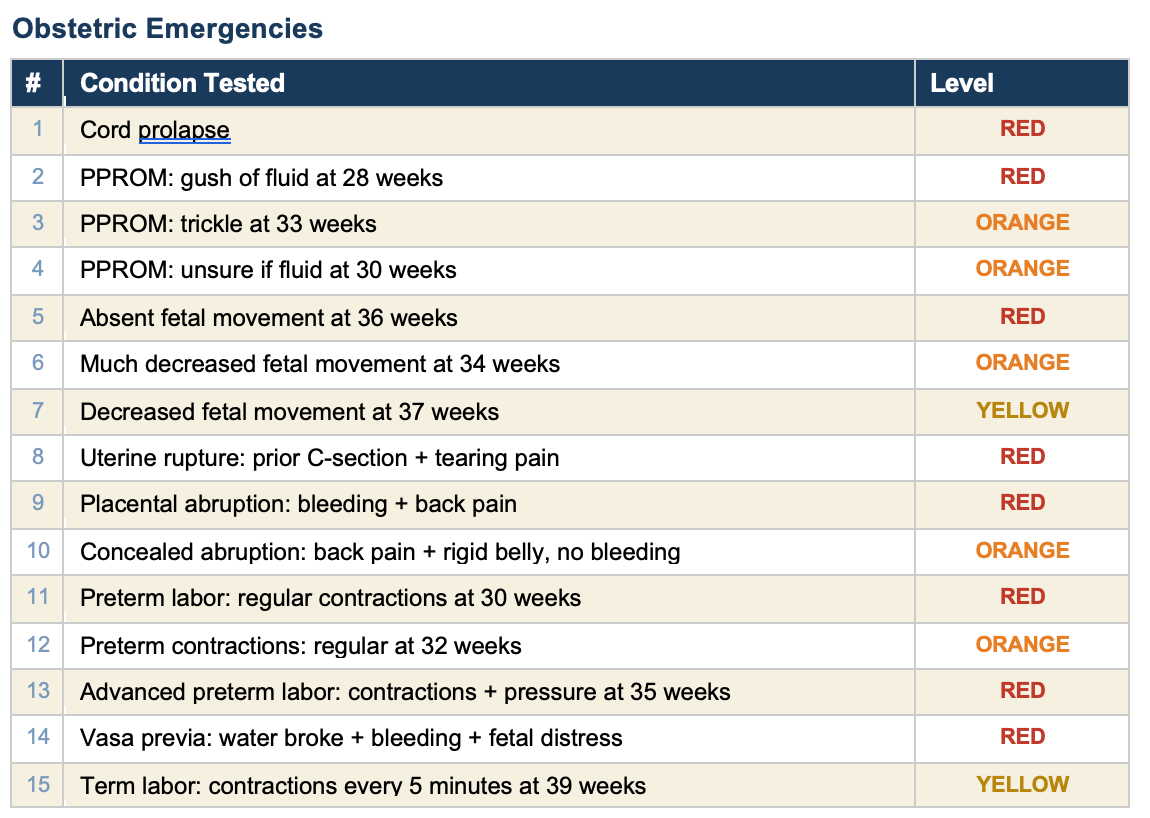
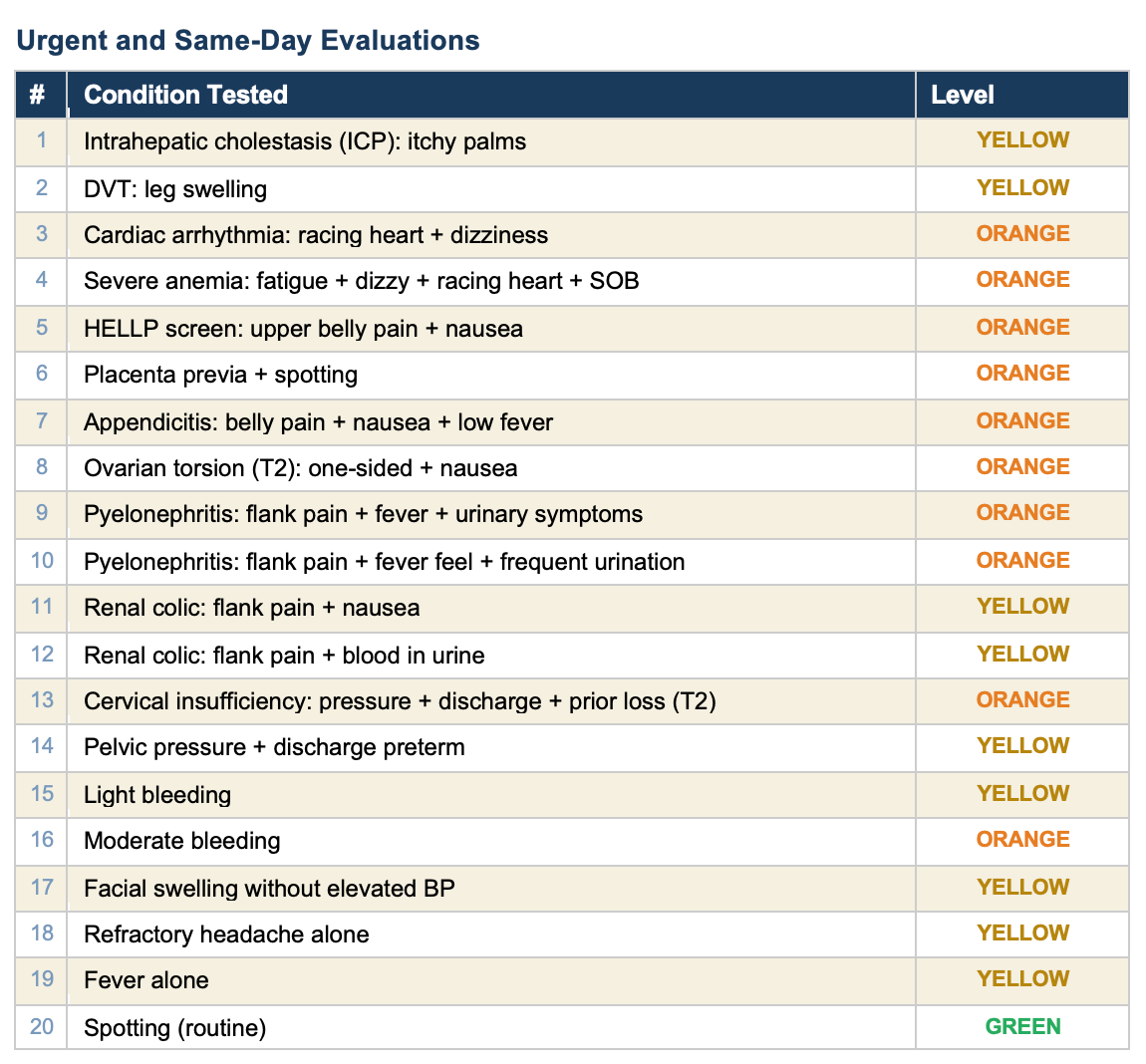
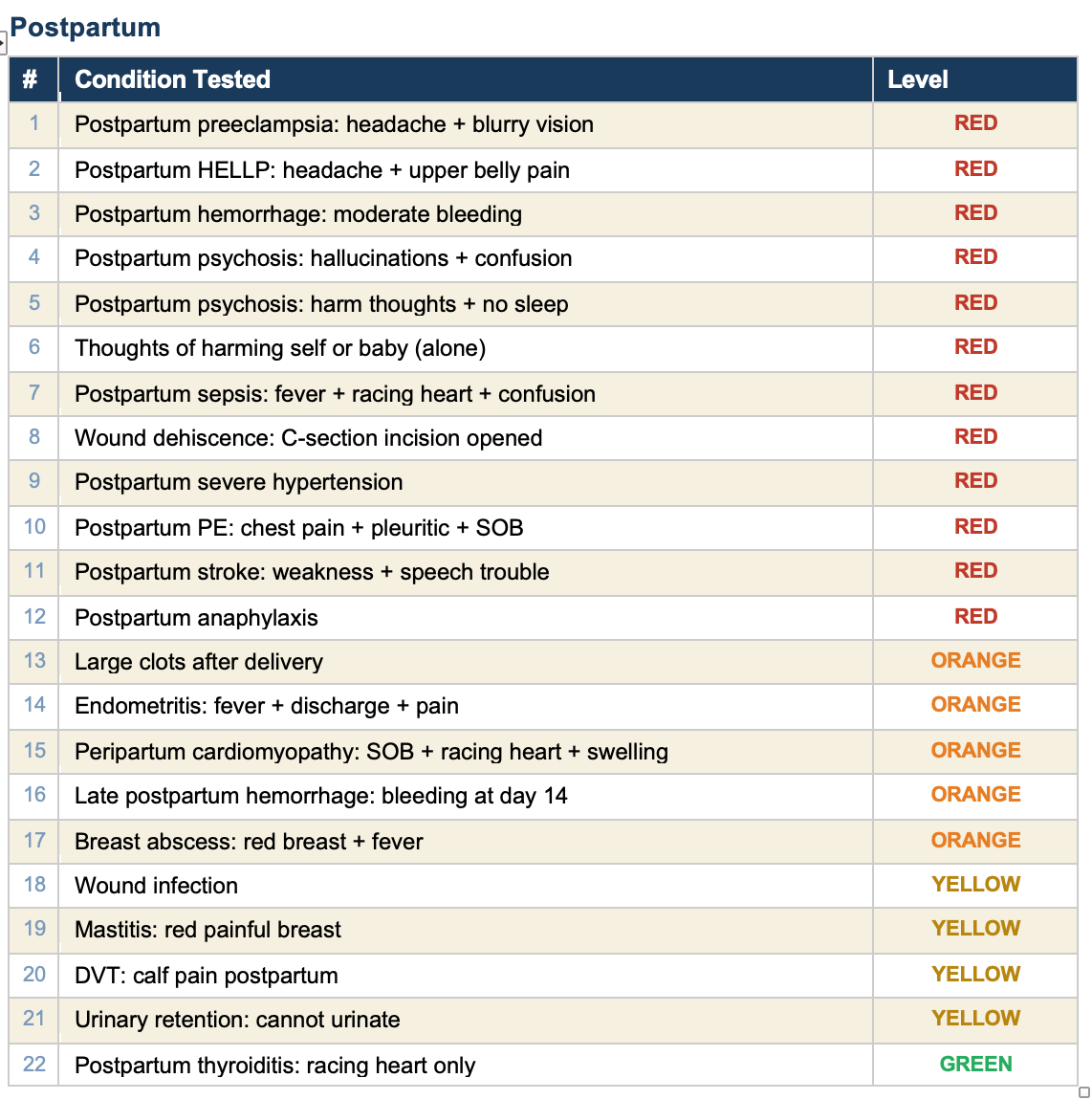
All 90 tests pass. Here is every condition we tested, organized by category.
What the self-test is, and what it is not
The self-test verifies that every rule in the engine fires correctly for the symptoms it is designed to detect. It confirms that the logic works: if you check “headache” and “blurry vision” at 30 weeks, the engine correctly flags preeclampsia with severe features and recommends the emergency room.
What it does not test is whether a real patient will check the right boxes. A woman experiencing HELLP syndrome may describe it as “stomach flu” and check “nausea” but not “upper belly pain.” The rules engine catches HELLP only when the right combination of symptoms is entered. That is the fundamental limitation of any rules-based system, and it is why the tool says: trust your body. If something feels wrong, go in regardless.
The self-test catches engineering failures. It does not catch human factors. Both matter.
My take
I have spent 50 years in maternal-fetal medicine. I have seen what happens when a woman walks into triage too late. The technology to help her recognize an emergency has existed for years. What has not existed is the will to make it simple, free, private, and honest about its limitations.
This tool covers 49 conditions across the full pregnancy timeline. Every one of them is tested. Every test passes. When a clinician finds a gap — a condition the tool misses or a scenario it handles wrong — we add a rule, add a test, and verify it works. The tool gets better and the proof is built in.
Not everything in medicine needs a chatbot. Some things just need clear rules, honest limitations, and the discipline to test them.
Excellent!